The NIRD RDA Ingest and Archive Workflow
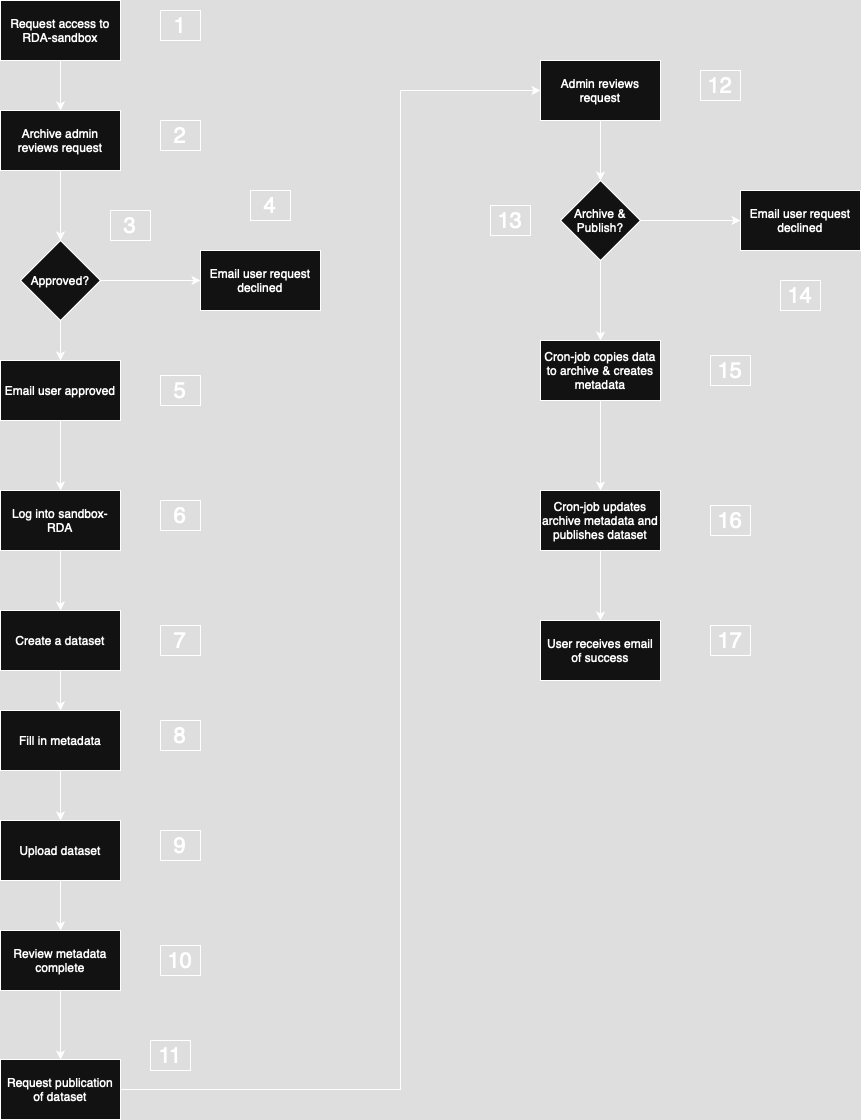 Figure 1: High-level view of the ingest and archive workflow.
Figure 1: High-level view of the ingest and archive workflow.
The figure shows the high-level workflow for archiving a dataseta in the NIRD RDA. A more detailed description of the ingest, archive and access processes is covered in the Preservation Plan.
Click on the ‘Sign In’ or ‘Addd Dataset’ button on the sandbox portal to access the archive. If you are a new user, you will be presented with a form to submit a request to access the archive.
The Archive administrator reviews the request to make sure the user satisfies the criteria for using the RDA-sandbox. The Archive administrator may contact the user for further information.
The Archive administrator either approves or rejects the request.
If the request is rejected, an email is sent to the user informing them that the request has been declined.
If the request is approved, an email is sent to the user informing them that the request has been successful.
The user can then log into the RDA-sandbox.
The user can create a new dataset first by accepting the Terms Of Use and Depositor Agreement.
Once accepted, the user is presented with a form in which to describe the dataset by filling in metadata fields.
The user can then upload the dataset either via the web interface, or from a project in the NIRD project area (NIRD Data Peak and/or NIRD Data Lake), or via a Command Line Interface. In the case of problems uploading the dataset, the user can contact the Archive Manager to help to understand and correct the problem.
After the dataset has been successfully uploaded, the user checks that the metadata describes the dataset, all the fields (mandatory and optional) have been completed and the correct license is applied to the dataset. The user then submits a request to publish the dataset.
The Archive administrator reviews the dataset, by checking all the metadata has been supplied, the dataset formats are open and the stakeholders agree to the dataset being published.
The Archive administrator then decides whether to publish the dataset.
If the administrator declines the request to publish, an email is sent to the user with a reason. In the case of resolvable issues, the user can work with the administrator to rectify the issuess and resubmit the dataset for publication.
Approval by the archive administrator creates an archiving cron job that copies the data from the import area to the archive, checksums the data and creates metadata at the file level for the dataset.
The archiving cron job updates the archive metadata that results in a request to DataCite to register the DOI for the dataset.
An email is sent to the user indicating the status of the archiving.